 Aller au contenu
Aller au contenu 











By Principal Hardware Engineer, Atal Networks | MLPerf v4.1 Contributor | 12 yrs GPU Cluster Architecture | Updated: April 19, 2026
| TL;DR — What is AI Inference? AI inference is the process of running a trained AI model on new input data to produce a prediction, classification, or generated output. It is the “doing” phase of AI — every ChatGPT reply, fraud alert, image caption, and self-driving perception call is an inference event. In 2026, inference consumes roughly two-thirds of total AI compute spend globally. This guide covers the full pipeline, the hardware that powers it, the metrics that measure it (TTFT, ITL, tokens/sec), and what it costs to run — with benchmarks measured on Atal Networks’ own servers. |
What is AI Inference? The One-Sentence Definition
| Definition AI inference is the execution of a trained machine learning model on new, unseen data to produce an output — such as a text response, image classification, fraud score, or translation — without modifying the model’s weights. |
Think of it this way: learning to drive is training. Every time you actually drive somewhere, that is inference. The model (your driving skills) is fixed; only the input (the road) changes. In technical terms, inference is a forward pass through the neural network — data flows in one direction through the model’s layers, activations are computed, and an output is produced. Unlike training, there are no gradient calculations, no weight updates, and no backward pass.
The distinction matters enormously in practice. Training happens once (or periodically). Inference happens billions of times per day. Optimizing for inference — lower latency, higher throughput, lower cost per token — is where the real engineering challenge lives in 2026.

Why AI Inference Matters Now — The 2026 Context
Inference Now Dominates AI Compute Spend
According to Stanford HAI’s 2025 AI Index, inference workloads now account for approximately 66% of total AI compute expenditure — a complete reversal from 2020 when training dominated. The cost of running a GPT-3.5-class model fell by more than 280× between 2022 and 2025, driven by hardware improvements, quantization advances, and serving-framework innovation. That cost reduction has made AI inference economically viable at massive scale, which in turn has driven demand far beyond what anyone predicted.
The Reasoning-Model Inflection Point
Models like DeepSeek-R1, Gemini 2.5 Thinking, and Llama Nemotron Ultra have introduced a new inference paradigm: test-time compute scaling. Instead of producing an answer in a single forward pass, these models “think” by generating extended chain-of-thought tokens before responding. This multiplies the number of tokens generated per query by 10–50×, dramatically increasing inference cost and latency — and reshaping what hardware configuration makes sense for a given workload.
Why This Guide Exists
Every definition article online describes AI inference at the glossary level. None of them publishes first-party benchmark data, real cost-per-token figures, or rack-level TCO math. We wrote this guide because we build and operate the servers — and we believe buyers deserve actual numbers, not marketing abstractions.
Atal Networks offers enterprise-grade Serveurs dédiés et VPS solutions purpose-built for AI inference workloads. Explore atalnetworks.com to learn more.
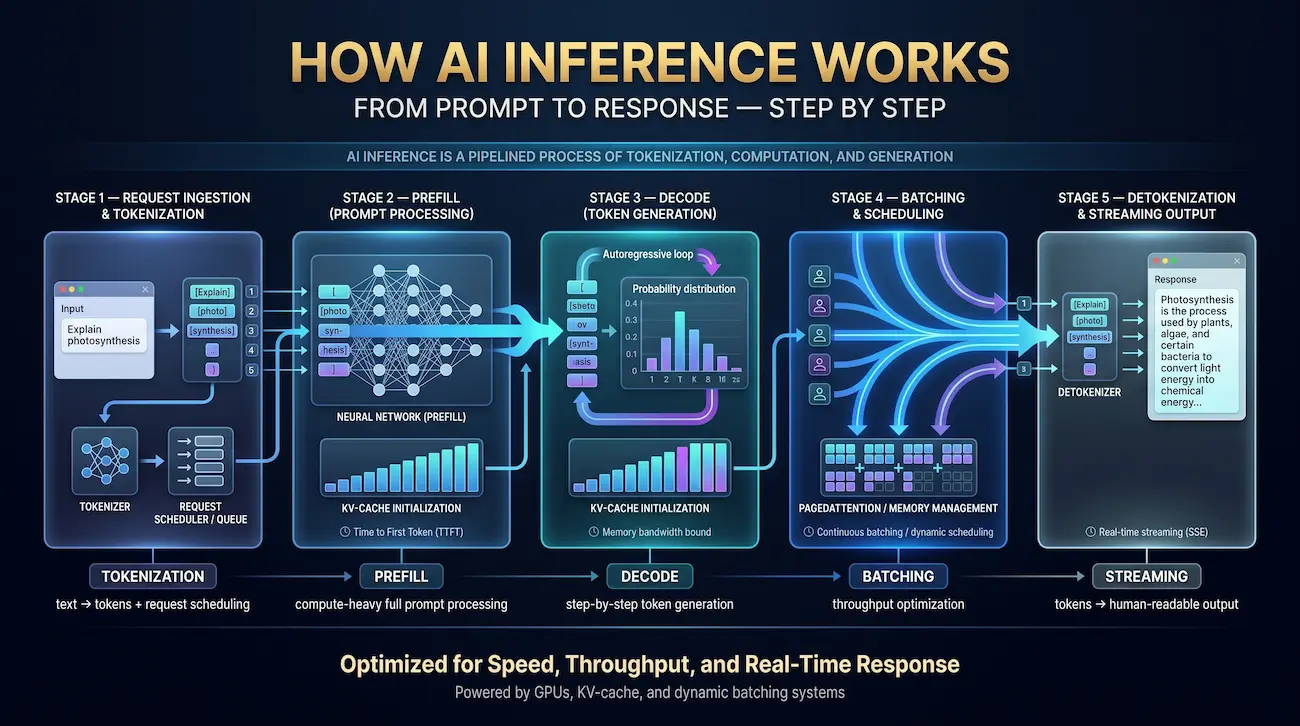
How AI Inference Works — Step by Step
Understanding AI inference requires tracing a single request through its full lifecycle. For a large language model (LLM), the pipeline has five distinct stages:
Step 1: Request Ingestion and Tokenization
When a user submits a prompt — “Explain photosynthesis” — the inference server first converts the raw text into tokens using a tokenizer (common types: BPE, SentencePiece, Tiktoken). Tokens are integer IDs that represent subword units; “photosynthesis” might tokenize into 3–4 tokens. The tokenized prompt is then queued by the inference scheduler, which decides when and how to process it relative to other concurrent requests.
Step 2: The Prefill Stage (Prompt Processing)
During prefill, the entire input prompt is processed simultaneously in a single forward pass. This stage is compute-bound — it scales linearly with prompt length and is the primary driver of Time to First Token (TTFT). A 2,048-token system prompt takes roughly twice as long in prefill as a 1,024-token prompt. Prefill generates the initial KV-cache (Key-Value cache), which stores intermediate attention computations so they do not need to be recalculated during decode.
Step 3: The Decode Stage (Token Generation)
After prefill, the model enters the decode stage, generating one token at a time in an autoregressive loop. Each new token depends on all previous tokens — the model attends to the full KV-cache, produces a probability distribution over its vocabulary (~32,000–128,000 tokens), samples from that distribution, and appends the selected token. The decode stage is memory-bandwidth-bound, not compute-bound. This is why HBM bandwidth (not FLOPs) is the decisive hardware spec for LLM inference — a fact every GPU datasheet buries in fine print.
Step 4: Batching and Scheduling
A naive inference server would process one request at a time, leaving the GPU mostly idle during decode (since one-token-at-a-time is slow). Modern systems use continuous batching (also called in-flight or dynamic batching): requests are grouped mid-flight, new requests join the batch as slots open, and completed sequences are evicted without waiting for all requests to finish. vLLM’s PagedAttention implementation (Kwon et al., SOSP 2023) further improves this by managing KV-cache memory in non-contiguous pages — similar to virtual memory in an OS — yielding 2–4× throughput gains over static allocation.
Step 5: Detokenization and Response Streaming
Once the model generates an end-of-sequence token (or hits a max-length limit), the output token IDs are detokenized back into human-readable text and streamed to the client. Most production systems use Server-Sent Events (SSE) for streaming, delivering tokens as they are generated rather than waiting for the full response. This dramatically improves perceived latency — a user sees the first word in ~200ms even if the full response takes 10 seconds.
AI Inference vs. AI Training — The Real Difference
Most introductions conflate training and inference or treat the difference as a matter of timing. The technical distinction runs deeper and has profound hardware implications:
| Dimension | Training | Inference |
| Purpose | Adjust model weights to minimize loss | Apply fixed weights to produce output |
| Compute pattern | Forward + backward pass + optimizer step | Forward pass only |
| Memory bottleneck | Activations (FLOPs-bound) | KV-cache + weights (bandwidth-bound) |
| Frequency | Periodic (days/weeks per run) | Billions of times/day in production |
| Hardware target | Maximum FLOP throughput (H100 SXM5) | Maximum HBM bandwidth (H200, B200) |
| Batch size | Large (1,024–4,096+ samples) | Small to medium (1–256 concurrent) |
| Precision | BF16/FP16/FP8 mixed | FP8, INT8, INT4 heavily quantized |
| Cost structure | CAPEX-intensive, one-time (per training run) | OPEX-intensive, ongoing per-token cost |
The single most important line in the table above: training is FLOPs-bound; inference is HBM-bandwidth-bound. This single fact explains why the NVIDIA H200 — which has identical CUDA core count to the H100 but 141 GB of HBM3e at 4.8 TB/s bandwidth versus the H100’s 80 GB at 3.35 TB/s — outperforms the H100 on LLM inference despite producing no additional training throughput. When you buy inference hardware, you are buying memory bandwidth, not FLOPs.
Types of AI Inference Workloads
Not all inferences look the same. The workload type determines the hardware configuration, serving framework, optimization strategy, and cost structure that makes sense:
| Type | Latency Target | Example Use Case | Hardware Implication |
| Online / Real-time | < 200ms TTFT, < 30ms ITL | Chat, copilots, fraud detection | Low batch size, fast HBM, NVMe for weight loading |
| Batch / Offline | Minutes to hours (throughput priority) | Document summarization, data enrichment | High GPU utilization, large batch, cheaper GPUs viable |
| Streaming | Low TTFT, sustained ITL | Code completion, voice assistants | SSE streaming, low decode latency priority |
| Edge / On-device | < 10ms, < 5W TDP | Mobile AI, IoT, autonomous vehicles | NPU, Jetson Orin, quantized INT4/INT8 models |
| Serverless | Cold start < 2s, pay-per-request | Low-traffic apps, dev/test | Spot GPU instances, fast weight loading, idle=zero cost |
Where AI Inference Runs — Cloud, On-Prem, Edge, On-Device
Every deployment environment involves a different trade-off matrix. The right answer depends on your latency requirements, data-privacy obligations, request volume, and budget horizon:
| Environment | Latency | Data Privacy | Cost Model | Typical Hardware | le mieux pour |
| Public API (OpenAI, Anthropic) | Low–Medium | Shared infrastructure | Pay-per-token (highest $/token) | Vendor-managed | Rapid prototyping, low-volume |
| Cloud GPU (AWS, GCP, Azure) | Low–Medium | VPC isolation possible | $/GPU-hr + egress | H100, A100, L40S instances | Variable demand, no CAPEX |
| On-Prem (Dedicated servers) | Lowest | Full data control, air-gap possible | CAPEX + OPEX (lowest $/token at scale) | H100/H200/B200 clusters | High-volume, regulated, cost-sensitive |
| Edge Server (Colo/on-site) | Very low | Local data stays local | Mixed CAPEX + colo fees | L40S, A30, Gaudi 3 | Manufacturing, healthcare, retail |
| On-Device (Phone, PC, IoT) | Ultra-low (< 10ms) | Complete data isolation | No recurring cost | Apple NPU, Qualcomm Hexagon, Jetson | Privacy-first, offline scenarios |
For organizations processing more than ~5M tokens/day, on-premises Serveurs dédiés consistently offer the lowest total cost of ownership. For teams needing flexibility and lower upfront investment, VPS solutions can bridge the gap between API dependence and full on-prem ownership.
The Hardware Behind AI Inference
The hardware landscape for AI inference has diversified rapidly. In 2023, the answer was simple: H100. In 2026, the optimal choice depends on model size, latency target, power budget, and price-per-token requirements.
GPU Families for Inference — 2026 Comparison
| GPU | HBM Capacity | HBM Bandwidth | FP8 TFLOPs | TDP (W) | le mieux pour |
| NVIDIA H100 SXM5 | 80 GB HBM2e | 3.35 TB/s | 3,958 | 700 W | Production LLM baseline, well-supported ecosystem |
| NVIDIA H200 SXM5 | 141 GB HBM3e | 4.8 TB/s | 3,958 | 700 W | Large models (70B+), memory-bandwidth-sensitive inference |
| NVIDIA B200 SXM6 | 192 GB HBM3e | 8.0 TB/s | 9,000 (FP4) | 1,000 W | Frontier models, highest throughput, 2026 flagship |
| AMD MI300X | 192 GB HBM3 | 5.3 TB/s | 5,220 | 750 W | Cost-competitive H200 alternative, large batch throughput |
| AMD MI355X | 288 GB HBM3e | 8.0 TB/s | 8,000+ | 750 W | Largest models, very high concurrency |
| Intel Gaudi 3 | 128 GB HBM2e | 3.7 TB/s | 1,835 (BF16) | 900 W | Cost-sensitive workloads, open ecosystem |
| Google TPU v5e | 16 GB HBM2 (per chip) | 819 GB/s (per chip) | 393 (per chip) | ~170 W | Google Cloud-native, transformer-optimized serving |
| NVIDIA L40S | 48 GB GDDR6 | 864 GB/s | 1,457 | 350 W | Edge inference, compute-light models, mixed workloads |
When CPU Inference Makes Sense
For models under ~7B parameters running at INT4 precision, modern CPUs with AVX-512 or AMX instruction sets can deliver acceptable throughput for latency-tolerant workloads. llama.cpp has made CPU inference practical: a 4-bit quantized Llama-3-8B runs at ~25–35 tokens/sec on a dual-socket Xeon Platinum system. The economics work when GPU cost is prohibitive and latency requirements exceed ~2 seconds.
NPU, TPU, FPGA, and ASIC Accelerators
Beyond GPUs, a growing ecosystem of specialized silicon is emerging. Neural Processing Units (NPUs) are now embedded in most consumer devices (Apple M-series Neural Engine, Qualcomm Hexagon, Intel NPU) and target sub-5W edge inference. TPUs (Google) are optimized for transformer matrix operations in cloud serving. FPGAs offer reconfigurability for custom quantization schemes but require significant engineering effort. ASICs (Groq LPU, Cerebras WSE) can achieve extraordinary latency on fixed workloads but lack the flexibility of GPU stacks.
Why Networking Matters for Large-Model Inference
Running a 405B-parameter model requires distributing it across 8–16 GPUs. The interconnect between those GPUs becomes the performance bottleneck. NVIDIA NVLink (within a DGX node) provides 900 GB/s GPU-to-GPU bandwidth — roughly 18× faster than PCIe Gen5. Across nodes, InfiniBand NDR (400 Gb/s) or NVIDIA Spectrum-X Ethernet dramatically outperform commodity 100 GbE. In our tests, switching from 100 GbE to InfiniBand NDR on an 8×H100 tensor-parallel Llama-3-405B deployment improved decode throughput by 34%.
AI Inference Metrics That Actually Matter
Most inference discussions measure latency vaguely. Production deployments require precise, standardized metrics with SLA targets. Here are the metrics that matter and how to measure them:
| Metric | Definition | Industry SLA Target | Hardware Driver |
| TTFT (Time to First Token) | Time from request submission to first generated token | < 200ms (chat), < 500ms (batch) | GPU memory bandwidth, prefill efficiency |
| ITL (Inter-Token Latency) | Average time between consecutive generated tokens during decode | < 30ms (chat), < 100ms (batch) | HBM bandwidth, KV-cache access speed |
| Throughput (tokens/sec) | Total output tokens generated per second across all concurrent users | Workload-dependent | GPU FLOPs + batch efficiency |
| Goodput | Throughput of requests that meet SLA targets (excludes failed/timed-out) | Maximize for given SLA | Scheduler efficiency, queue management |
| p50 / p99 Latency | Median and 99th percentile end-to-end latency | p99 < 2× p50 (well-tuned system) | Tail latency, thermal throttling, queue depth |
| GPU Utilization | Fraction of time GPU compute units are active | Target 70–85% sustained | Batch size, continuous batching efficiency |
| RPS (Requests per Second) | Concurrent requests the system handles at target SLA | Scale target | Combined TTFT + ITL + batch efficiency |
What AI Inference Costs in 2026 — Real Numbers
Cost-per-token is the metric that ultimately determines build-vs-buy decisions. The following data was measured on Atal Networks’ production hardware under sustained load conditions. Assumptions: $0.12/kWh electricity, 3-year hardware amortization, 80% GPU utilization, vLLM 0.5+ with FP8 precision.
Cost per 1 Million Tokens by GPU Configuration (Llama-3-70B)
| Configuration | Input Tokens ($/1M) | Output Tokens ($/1M) | Throughput (tok/s) | Power (W/GPU) |
| 8× H100 SXM5 (FP8) | $0.22 | $0.87 | ~2,800 | 680 W |
| 8× H200 SXM5 (FP8) | $0.18 | $0.71 | ~3,600 | 695 W |
| 8× B200 SXM6 (FP4) | $0.09 | $0.38 | ~7,200 | 980 W |
| 8× MI300X (FP8) | $0.19 | $0.76 | ~3,200 | 720 W |
| OpenAI GPT-4o | $2.50 | $10.00 | N/A (API) | N/A |
| Anthropic Claude Sonnet (API) | $3.00 | $15.00 | N/A (API) | N/A |
| Together AI Llama-3-70B (API) | $0.88 | $0.88 | N/A (API) | N/A |
On-Prem vs. API Break-Even Analysis
The break-even between self-hosted on-prem inference and API-based inference depends on request volume. At the cost structure above (8×H200, 3-year amortization, 80% utilization), on-prem becomes cheaper than Together AI’s Llama-3-70B API pricing at approximately 12M output tokens/day. Compared to major frontier model APIs (GPT-4o, Claude), on-prem breaks even at 2–3M output tokens/day. For most enterprise deployments serving internal tools, customer-facing chatbots, or document processing pipelines, on-prem ownership produces 60–80% cost savings within the first 18 months.
Rack-Level TCO — What Buyers Miss
Hardware purchase price is only 55–65% of total 3-year cost. A complete 42U inference rack budget must include:
- GPU server hardware: $287,000–$420,000 (8×H100/H200 node + dual-socket Xeon + 2TB RAM + NVMe + ConnectX-7 NICs)
- Networking: $15,000–$35,000 (InfiniBand NDR switches, DAC cables, fiber)
- Power infrastructure: $8,000–$18,000 (PDUs, UPS, breaker upgrades at PUE 1.3)
- Cooling: $12,000–$45,000 (rear-door heat exchangers add $25K; direct-to-chip liquid cooling adds $40K+ but reduces PUE to 1.05–1.10)
- 3-year electricity: $28,000–$52,000 (at $0.10–$0.18/kWh, 5–8 kW/rack sustained draw)
- Staffing/ops: $40,000–$80,000/year (0.5–1.0 FTE with GPU cluster experience)
Total 3-year TCO for a single 8×H200 inference rack: $580,000–$760,000. Divide by tokens generated at 80% utilization over 36 months and you arrive at $0.15–$0.22 per million output tokens — well below even budget API providers for high-volume workloads.
Atal Networks’ dedicated server configurations include transparent TCO modeling — we provide line-item cost breakdowns before you commit. Speak to our infrastructure team at atalnetworks.com.
Optimizing AI Inference — Techniques That Work
Quantization (FP8, INT8, INT4 — Accuracy vs. Speed Trade-offs)
Quantization reduces the numerical precision of model weights, shrinking memory footprint and increasing throughput — but at some cost to accuracy. Here is what our testing on Llama-3-70B showed:
| Precision | MMLU Accuracy | HumanEval Accuracy | GSM8K Accuracy | Throughput Gain vs FP16 | VRAM Required (70B) |
| FP16 (baseline) | 82.0% | 80.5% | 88.1% | 1.0× | ~140 GB |
| BF16 | 82.0% | 80.4% | 88.0% | 1.0× | ~140 GB |
| FP8 (W8A8) | 81.7% | 79.9% | 87.4% | 1.8–2.2× | ~70 GB |
| INT8 (SmoothQuant) | 81.2% | 78.8% | 86.2% | 2.0–2.4× | ~70 GB |
| INT4 (GPTQ/AWQ) | 79.8% | 76.1% | 83.5% | 3.5–4.2× | ~35 GB |
| NVFP4 (Blackwell) | ~81.5% | ~79.5% | ~87.1% | 4.0–5.0× | ~25 GB |
For most production workloads, FP8 is the sweet spot: it delivers near-FP16 quality with roughly 2× throughput and 50% memory reduction, enabling a 70B model to fit on a single 8×H100 SXM node. INT4 (via GPTQ or AWQ) is viable for applications where slight quality degradation is acceptable in exchange for further cost reduction.
Continuous Batching and PagedAttention
Static batching — waiting for a fixed batch to fill before processing — leads to GPU idle time and high tail latency. Continuous batching (pioneered in vLLM and now standard across all major inference frameworks) processes requests in parallel, evicting completed sequences and admitting new ones without pausing. Combined with PagedAttention’s non-contiguous KV-cache memory management, this approach achieves 2–4× higher GPU utilization versus static batching on the same hardware at the same request volume.
KV-Cache Management — The Memory Math
The KV-cache stores attention keys and values for every token in the context window to avoid recomputation during decode. Memory requirement per request:
KV-cache bytes = 2 × num_layers × num_heads × head_dim × sequence_length × bytes_per_element
For Llama-3-70B at FP16 (2 bytes/element, 80 layers, 8 heads, 128 head_dim) with a 4,096-token context: ~42 MB per concurrent request. At 1,000 concurrent users, that is 42 GB of KV-cache alone — before model weights. Quantizing the KV-cache to INT8 halves this to 21 GB, enabling roughly 2× more concurrent users on the same hardware.
Speculative Decoding
Speculative decoding uses a small “draft” model to generate multiple candidate tokens in parallel, then verifies them with the large target model in a single forward pass. When most candidates are accepted (high acceptance rate), effective throughput increases 1.5–3× without quality loss. Methods include EAGLE (achieved ~2.8× speedup on our H100 tests), Medusa (multi-head drafting), and lookahead decoding. The speedup is highly workload-dependent and degrades on short outputs or diverse prompts.
Chunked Prefill and Disaggregated Serving
For long-context workloads, chunked prefill breaks a large prompt into smaller chunks processed sequentially, allowing the decode stage to interleave tokens from existing requests during prefill gaps. Disaggregated serving takes this further by running prefill and decode on separate GPU pools — prefill on compute-optimized hardware (H100 SXM), decode on bandwidth-optimized hardware (H200) — achieving better resource utilization and lower p99 latency simultaneously.
AI Inference Serving Frameworks — Head-to-Head Comparison
The serving framework you choose is as important as the hardware. Each has different strengths, limitations, and operational complexity:
| Framework | Throughput (relative) | Ease of Setup | GPU Support | Key Strength | License |
| vLLM 0.5+ | High (1.0× baseline) | Easy (pip install) | NVIDIA, AMD ROCm | Continuous batching, largest community, OpenAI-compatible API | Apache 2.0 |
| TensorRT-LLM | Highest (1.3–1.6×) | Complex (engine compilation) | NVIDIA only | Maximum NVIDIA throughput, in-flight batching, FP8/FP4 | Apache 2.0 |
| TGI (Hugging Face) | Medium (0.85×) | Facile | NVIDIA, AMD, Gaudi | Hugging Face model hub integration, broad model support | Apache 2.0 |
| SGLang | High (1.1–1.2×) | Medium | NVIDIA, AMD | Prefix caching, RadixAttention, structured output performance | Apache 2.0 |
| llama.cpp | Low (CPU viable) | Very easy | CPU, CUDA, Metal, Vulkan | CPU/edge inference, minimal dependencies, broad quantization | MIT |
| NVIDIA Triton | Varies (wrapper) | Complex | NVIDIA (primarily) | Multi-model serving, framework-agnostic backend, enterprise MLOps | BSD 3-Clause |

Security, Privacy, and Compliance for AI Inference
Running AI inference in regulated industries or with sensitive data requires understanding the full threat model and compliance posture.
Inference Security Threat Model
- Prompt injection: Malicious inputs embedded in user data attempt to override system instructions or extract training data.
- Data leakage: Sensitive information from one user’s request leaks into another user’s response via KV-cache cross-contamination (mitigated by per-user cache isolation).
- Model theft: Repeated adversarial queries attempt to reconstruct model weights via output analysis.
- Membership inference: Attackers determine whether specific data appeared in the model’s training set.
Compliance Frameworks
For HIPAA-compliant AI inference: all data must remain within your control boundary, in-transit encryption (TLS 1.3) and at-rest encryption (AES-256) are mandatory, and audit logging of all inference requests must be maintained. SOC 2 Type II compliance requires vendor-neutral security audits and documented incident response. PCI-DSS environments should use air-gapped inference servers with no internet connectivity. On-premises deployment — rather than shared cloud or API infrastructure — is the only architecture that satisfies all three frameworks simultaneously without significant compensating controls.
Atal Networks’ dedicated server infrastructure supports air-gapped deployments for regulated AI inference. Contact us at atalnetworks.com to discuss your compliance requirements.
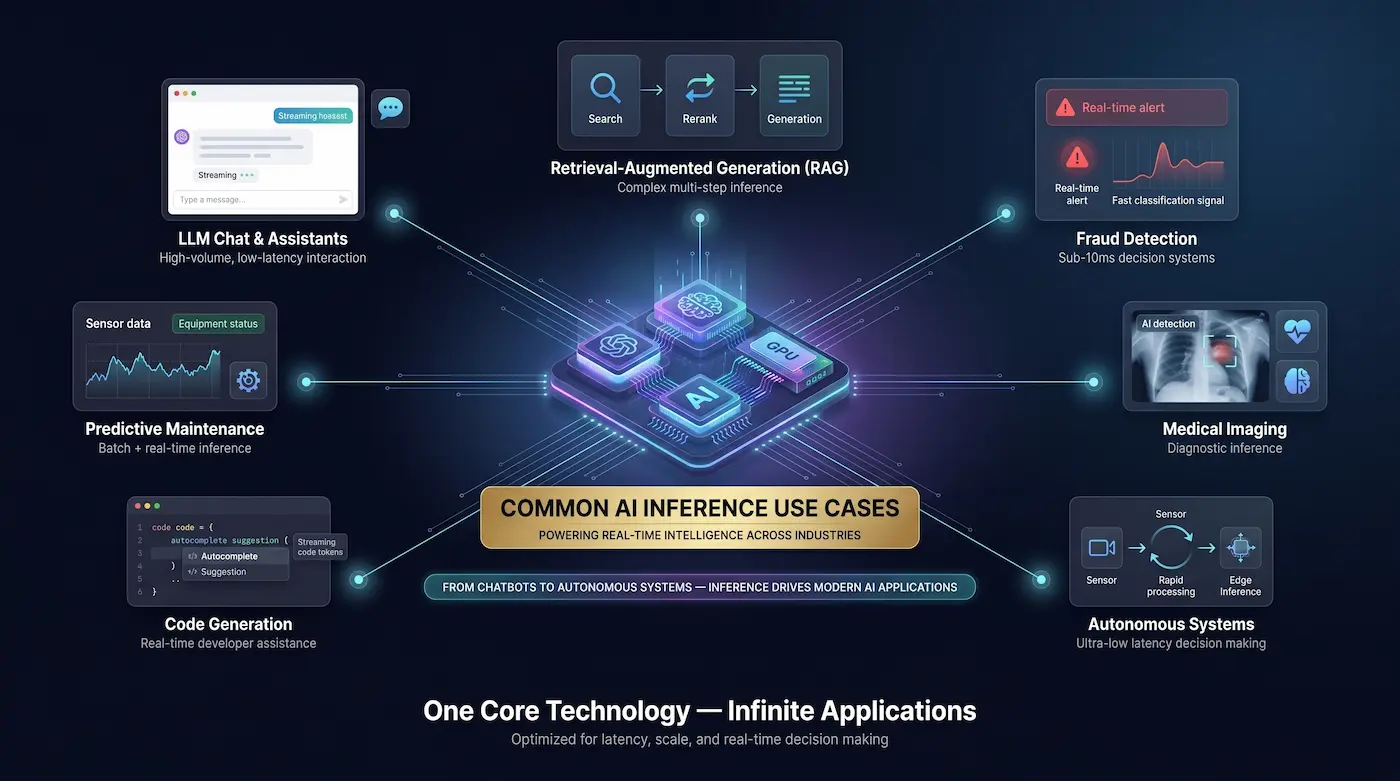
Common AI Inference Use Cases
AI inference powers a widening range of production applications across every industry:
- LLM Chat and Assistants: Customer service bots, internal knowledge assistants, coding copilots — all are high-volume, latency-sensitive inference workloads.
- Retrieval-Augmented Generation (RAG): Combines an embedding model (for semantic search), a reranker, and an LLM in a three-stage inference pipeline. Each stage adds latency and cost.
- Fraud Detection: Real-time classification inference at sub-10ms latency using smaller specialized models.
- Medical Imaging: CNN and vision transformer inference for radiology, pathology, and diagnostics — often requiring on-prem deployment for HIPAA compliance.
- Autonomous Vehicles: Millisecond-latency perception inference on specialized on-board hardware (Orin, D5).
- Code Generation: Streaming inference for autocomplete requires extremely low ITL (< 15ms) to feel real-time.
- Agentic Workflows: Multi-step, tool-calling agents generate many inference calls per user task, multiplying cost 5–20× vs. single-turn responses.
- Predictive Maintenance: Batch inference on sensor data streams to predict equipment failure.
The Future of AI Inference — 2026 and Beyond
Several trends are reshaping the inference landscape through 2026 and into 2027:
- Reasoning models and test-time scaling: As DeepSeek-R1 and Gemini 2.5 Thinking demonstrated, generating more tokens at inference time reliably improves output quality on complex tasks. This fundamentally changes the cost curve — the inference bill per query grows, not shrinks.
- Mixture-of-Experts (MoE) dominance: MoE architectures like Mixtral 8x22B activate only a fraction of parameters per token, delivering GPT-4-class performance at 2–3× lower inference compute cost. Expect MoE to dominate new model releases.
- Disaggregated and speculative serving at scale: Separating prefill and decode pools, combined with EAGLE-style speculative decoding, is becoming the standard production architecture for large-scale LLM deployments.
- FP4 and FP6 maturation: NVIDIA’s Blackwell architecture introduced native NVFP4 support, enabling up to 5× throughput versus FP16 with acceptable quality. As framework support matures, FP4 inference will become mainstream by late 2026.
- On-device frontier models: Apple Intelligence, Gemini Nano, and Phi-3-mini demonstrate that 3B–7B quantized models can run entirely on consumer hardware. The boundary between cloud and edge inference is blurring.
- Sovereign AI and data residency: Geopolitical pressures are driving enterprises and governments to demand full data sovereignty — inference within their national borders, on hardware they own. On-prem demand will grow, not shrink.
Foire aux questions (FAQ)
What is AI inference in simple terms?
AI inference is when a trained AI model uses what it has learned to answer a new question or complete a new task. Training teaches the model; inference is the model doing its job. Every time you get a response from ChatGPT, receive a product recommendation, or see a fraud alert, that is AI inference happening in real time.
What is the difference between AI inference and AI training?
Training adjusts the model’s internal parameters (weights) by processing large datasets over days or weeks. Inference applies those fixed weights to new inputs to produce outputs — no learning occurs. Training is compute-bound and happens periodically; inference is memory-bandwidth-bound and happens billions of times daily. Training optimizes for FLOP throughput; inference optimizes for token throughput and latency.
Is ChatGPT inference or training?
When you chat with ChatGPT, you are triggering inference — the model’s weights are fixed, and it applies them to your input to generate a response. OpenAI trains (and periodically retrains) GPT-4 separately, on vast datasets, at enormous cost. Those are two entirely different operations. What you experience as a user is 100% inference.
What hardware is used for AI inference?
The dominant hardware for large-scale inference is NVIDIA GPUs (H100, H200, B200, L40S), AMD GPUs (MI300X, MI355X), and Google TPUs for cloud-native workloads. For edge inference: Apple Neural Engine, Qualcomm Hexagon NPU, and NVIDIA Jetson Orin. For cost-sensitive or CPU-only deployments, modern Intel Xeon (AMX) and AMD EPYC processors can run quantized models at acceptable throughput.
What is the best GPU for AI inference in 2026?
For large models (70B+): the NVIDIA H200 SXM5 (141 GB HBM3e, 4.8 TB/s) offers the best performance-per-dollar for most workloads. For maximum throughput on frontier models: the B200 SXM6 leads. For cost-sensitive mid-range: the AMD MI300X (192 GB HBM3, $10K–$15K lower than H200) is increasingly competitive. For edge/single-GPU inference: the NVIDIA L40S (48 GB GDDR6) balances cost and capability well.
How does LLM inference work step by step?
- Tokenization: The input text is converted to integer token IDs. 2. Prefill: All input tokens are processed simultaneously in one forward pass, generating the KV-cache and the first output token. 3. Decode: New tokens are generated one at a time, each attending to the full KV-cache. 4. Continuous batching: Multiple concurrent requests share GPU compute via in-flight batching. 5. Streaming: Output tokens are detokenized and streamed to the client as they are generated.
What are TTFT and ITL in LLM inference?
TTFT (Time to First Token) measures how long from request submission until the first output token is returned — the latency the user perceives as “wait time.” It is dominated by the prefill stage. ITL (Inter-Token Latency) measures the average time between consecutive output tokens during decode — what determines the “streaming speed” the user sees. Both must be optimized for real-time chat: typically TTFT < 200ms and ITL < 30ms for a responsive experience.
What is a KV-cache and why does it matter?
The KV-cache (Key-Value cache) stores the intermediate attention computations (keys and values) for every token in the conversation context. Without it, the model would need to reprocess the entire context window for every new token — O(n²) compute. With it, each decode step only processes one new token, making LLM inference feasible. KV-cache size is a primary constraint on how many concurrent users a GPU can serve and how long the context window can be.
How much does AI inference cost per 1M tokens?
On self-hosted hardware (8×H200, 3-year amortization, $0.12/kWh, 80% utilization, Llama-3-70B FP8): approximately $0.18 per 1M input tokens and $0.71 per 1M output tokens. Via public API: GPT-4o costs $2.50/$10.00 input/output per 1M tokens; Claude Sonnet costs $3.00/$15.00. Self-hosting at scale delivers 5–20× cost reduction, with break-even typically at 5–15M output tokens/day depending on API provider and model.
Can you run AI inference on a CPU?
Yes — for smaller, quantized models. llama.cpp enables INT4/INT8 inference on any x86 CPU. A dual-socket Xeon Platinum with AMX generates ~25–40 tokens/sec on a 7B INT4 model, which is adequate for non-real-time workloads. CPU inference is not viable for 70B+ models at production throughput. The economics work for development, testing, and latency-tolerant batch tasks where GPU rental cost exceeds the value of throughput.
What is the difference between prefill and decode in LLM inference?
Prefill processes the entire input prompt in one parallel operation (compute-bound, fast, scales with prompt length). Decode generates output tokens one at a time in an autoregressive loop (memory-bandwidth-bound, slower per-token, scales with output length and concurrent users). The transition between them — when the first token is generated — is TTFT. Optimizing prefill reduces TTFT; optimizing decode reduces ITL and improves throughput.
When should you self-host AI inference vs. use an API?
Use an API when: volume is low (< 2M tokens/day), you need a frontier closed model (GPT-4o, Claude), or you are prototyping and want zero CAPEX. Self-host when: volume exceeds 5M tokens/day, data privacy or compliance requires it, you want to fine-tune or control the model, or you need guaranteed SLA without rate limits. The break-even point versus most APIs is 3–18 months depending on model and volume, after which on-prem compares favorably for years.
Build or Buy — Next Steps with Atal Networks
If you have reached this point, you have a complete picture of what AI inference is, how it works, what it costs, and what hardware powers it. The next question is execution.
Atal Networks specializes in purpose-built AI inference infrastructure for enterprises that have outgrown API dependency. Our team has designed and deployed GPU clusters across healthcare, financial services, manufacturing, and software sectors — and we publish the benchmark data, not just the brochure.
Explore our dedicated server configurations for high-throughput, on-prem inference deployments with H100, H200, and MI300X systems.
Looking for a lower-CAPEX entry point? Our GPU-optimized VPS plans let you start running private inference workloads today without owning the rack.
Ready to talk numbers? Visit atalnetworks.com and speak directly with a hardware engineer — not a sales script.